Per poter accedere anche solo
in modo superficiale alle risorse di rete è bene conoscere alcune
nozioni fondamentali ai fini di una corretta ricerca su OPAC e banche dati..
La conoscenza seppur minimale
delle modalità di ricerca più elementari, l'utilizzo degli
operatori di ricerca e di una corretta sintassi, sono indispensabile ai
fini una ricerca bibliografica anche a livello di semplice interrogazione.
La struttura dei record
I data base sono organizzati in record che a loro volta si suddividono
in campi o field con delle etichette di campo che contraddistinguono il
campo stesso (i TAG), a seconda del formato del record.
Le informazioni che compongono il record bibliografico, utili ad
identificare il documento sia per il suo contenuto che per la sua collocazione
nella fonte primaria (citazione bibliografica completa di un abstract),
sono quindi strutturate in campi (fields) che nel loro insieme formano
un determinato dato (o record); l'insieme di questi record strutturati
crea il database.
Ogni database e' quindi specifico sia per l'ambito disciplinare
di cui raggruppa le informazioni, sia per la struttura interna delle stesse
informazioni.
Interrogazione del database
Linterrogazione dei database può avvenire :
1. utilizzando termini controllati tratti dal Thesaurus o da uno
Schema di Classificazione (qualora presente)
2. utilizzando termini liberi (textwords) all'interno di tutti i
campi o in determinati campi
3. consultando lIndex, (se presente) per controllare l'esatta sintassi
dei termini che si vogliono utilizzare
Larticolazione della strategia di ricerca e quindi la combinazione dei termini ricercati avviene grazie allutilizzo degli operatori di ricerca (operatori booleani, di prossimità, di campo, matematici), all'uso di simboli, talvolta diversi da un database all'altro, a seconda del tipo di linguaggio per il recupero dell'informazione collegato al database.
RICERCA PER TERMINI CONTROLLATI DA THESAURUS
La consultazione del thesaurus
va considerata la via di accesso preferenziale alle banche dati perché
luso di una parola chiave
che esprima univocamente
il concetto da ricercare
dà garanzia sul contenuto dei documenti recuperati
Il Thesaurus è il dizionario di termini
controllati (o descrittori o parole chiave) del database.
E sottoposto a continuo aggiornamento con
aggiunta di termini descrittori nuovi che rispondono a nuovi indirizzi
di ricerca ed eliminazione di quelli obsoleti.
Ogni documento viene indicizzato, per quanto
riguarda il contenuto, con tanti descrittori quanti sono gli argomenti
trattati. Se l'utente utilizza come strumento di ricerca un descrittore
del tesauro vedrà recuperati tutti i documenti che contengono tale
descrittore tra quelli assegnati.
Linterrogazione del Thesaurus permette
di visualizzare, oltre che la lista alfabetica dei descrittori, anche tutta
la struttura gerarchica dell'albero classificatorio.
RICERCA PER TERMINI LIBERI
L'utilizzo di termini liberi
(textwords) tratti dal linguaggio naturale avvia una ricerca basata esclusivamente
sulla presenza di una parola (o di una espressione) in un qualsiasi campo
del record. Il risultato può essere, rispetto ad un'analoga ricerca
svolta in Thesaurus, numericamente superiore ma qualitativamente meno pertinente
all'argomento della ricerca.
Può essere ricercata
una parola singola oppure un'espressione composta da due o più parole.
In questo ultimo caso i termini che compongono l'espressione vengono cercati
dal sistema secondo il principio dell'adiacenza e cioè uno accanto
all'altro, anche invertiti nell'ordine, ma senza nessun altro termine intermedio
Es.: Insulin delivery
Islet cell transplantation
Uso delle parentesi
Nelle ricerche che combinano due termini (liberi o descrittori) e che
vengono poi limitate con l'operatore di campo in, è possibile utilizzare
le parentesi per rendere più breve la procedura
Es.: (therapy and aids) in TI
ricerca entrambi i termini nel titolo
therapy and aids in TI
ricerca therapy in tutti i campi e aids solo nel titolo.
Troncamento
I termini inseriti per la ricerca con parola libera possono essere
troncati con il simbolo *(asterisco), oppure in alcuni linguaggi
di ricerca con segno $ (dollaro) per cercare la parola in tutte
le sue possibili variazioni oltre la radice
Es.: model* trova model, models,
modeling, modelling, etc.
Uso delle Wildcard
Il simbolo ? (punto interrogativo) oppure in alcuni linguaggi
di ricerca il segno # permette di sostituire un carattere
su cui ci sia incertezza, all'interno di un termine che può avere
varianti grafiche; possono essere dati tanti ? quanti sono i caratteri
incerti o sconosciuti.
Es.: volley?ball (per recuperare i documenti
in cui il termine è presente in forme varianti: volley-ball
oppure volleyball)
behavio?r (cerca questa parola sia
nella forma behavior che in quella behaviour).
RICERCA DA INDEX
La ricerca può essere effettuata anche partendo dalla consultazione dell'Index (se esistente) che costituisce lindice alfabetico della base di dati poiché elenca termini liberi, descrittori, nomi propri, titoli di riviste, sigle e talvolta riporta le occorrenze per ogni termine.
LIndex va considerato un
supporto alla ricerca con parola libera soprattutto per quanto riguarda
autori e titoli di riviste. Il caso frequente è costituito dalla
ricerca di autori russi con translitterazioni inglesi piuttosto che italiane,
per autori con nome composto: l'Index visualizza le varie forme utilizzate
(con iniziali oppure per esteso, complete del prenome oppure abbreviate)
e permette all'utente di effettuare una scelta delle forme ritenute più
idonee a garantire un recupero il più possibile completo dei dati.
Permette comunque una rapida
visualizzazione dei termini liberi e controllati a partire da un certo
termine o radice di esso
RICERCA PER CAMPI LIMITE O CON FILTRI
Molte interfacce prevedono
una differenziazione, in due fasi distinte, due momenti concettuali diversi,
anche conseguenti, nella formulazione della ricerca.
Vi possono quindi essere
due blocchi con stringhe di ricerca per campi chiave:
il primo blocco con almeno
un campo da riempire obbligatoriamente, con campi effettivamente ricercabili
autonomamente o in alternativa tra loro,
il secondo blocco con campi
chiave facoltativi e che comunque non possono essere utilizzati autonomamente
per la ricerca, in quanto condizionati ad una ricerca in abbinamento ai
campi chiavi primari.
Si tratta quindi di un "raffinamento"
per limiti di campo, o per "filtri" che sono comunque legati alla ricerca
dei campi chiave primari
GLI OPERATORI DI RICERCA
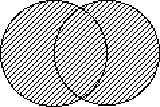
Operatori Logici Booleani
AND, OR, NOT permettono larticolazione
della ricerca mettendo in relazione tra di loro due o più termini:
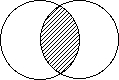
AND : Loperatore AND permette
di selezionare documenti che contengano un concetto definibile da più
termini specifici. Esso permette un raffinamento tra documenti che possono
risultare generici o comprendere concetti non utili per lindividuazione
dei testi cercati.
Recupera i documenti in cui
sono presenti entrambi i termini di ricerca
stress AND anxiety
tutti i documenti con la parola o il descrittore
stress e tutti quelli con la parola o il descrittore anxiety
presenti contemporaneamente nel record.
OR : Loperatore OR seleziona
documenti che contengono più concetti.
Questi possono essere contenuti
nei testi in combinazione con altri od essere presenti in maniera isolata.
Il risultato della ricerca fornirà documenti che contengano anche
uno solo degli elementi cercati.
Recupera i documenti in cui
sia presente almeno 1 dei 2 termini di ricerca.
stress OR anxiety
tutti i documenti con la parola o il descrittore
stress, tutti quelli con la parola o il descrittore anxiety
e tutti quelli che hanno sia stress sia anxiety.
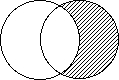
NOT : Loperatore NOT permette
un raffinamento tendente ad escludere alcuni concetti non interessanti
ai fini della ricerca. Linsieme di documenti ottenuto non conterrà
elementi che possano generalizzare e non centrare la ricerca.
Recupera i documenti in cui
è presente il termine di ricerca ma senza recuperare i documenti
ove vi sia l'altro termine, associato con il NOT, che invece non deve essere
presente
stress NOT anxiety
solo i documenti con la parola stress
escludendo tutti quelli con la parola anxiety
N.B.: Elimina anche i records in cui sono
presenti entrambi i termini
Operatori di prossimità
ADJ : Operatore che permette di associare due termini ravvicinati creando una locuzione di ricerca. Non sempre è necessario digitarlo in quanto in alcuni sistemi è sufficiente digitare i due termini vicini.
WITH : Permette di recuperare i documenti in cui i termini associati in ricerca sono presenti all'interno dello stesso campo (il dato o record è strutturato in campi). Perciò la ricerca dei due termini associati viene effettuata campo per campo e il recupero è finalizzato ai soli record in cui i due termini sono presenti all'interno di uno stesso campo
NEAR : Recupera i documenti in cui i termini cercati sono contenuti all'interno di una stessa frase. Il campo quindi può contenere più 'sentence' o frasi, per esempio i campi contenenti sommari, abstract, recensioni. NEAR ricerca i due termini all'interno di uno stesso campo e all'interno di una stessa frase.
NEARn : Dove per n si indende un carattere
numerico che si riferisce al numero di parole massimo che possono essere
presenti tra i due termini di ricerca.
Pertanto l'uso di questo operatore permetterà
di recuperare necessariamente record ove i due termini saranno presenti
non solo all'interno di uno stesso campo, non solo all'interno di una stessa
frase, ma vicini tra loro ad una distanza massima pari al valore di n.
Es.: Stress NEAR1 therapy: stress-reduction
therapy
stress-coping therapy
therapy-related stress
Fear NEAR1
flying fear of flying
flying fear
Operatore di frequenza o di rilevanza. Permette
di specificare una soglia di occorrenze per un dato termine.
Questo operatore è particolarmente
utilizzato nelle ricerche su database full-text all'interno del campo (TX)
al fine di individuare la ricorrenza di un
determinato termine o frase.
Assicura quindi il recupero dei documenti
che soddisfano una determinata condizione: limite minimo di volte che una
parola/termine o frase compare all'interno del campo TX
La sintassi per questo operatore può
essere data in questo modo
"x.fd./freq=n",
dove x è la condizione, fd è il tag (etichetta di campo) del nome del campo, e n è il numero di soglia minimo di frequenza
Esempio: "blood pressure.tx./freq=10"
recupererà solo quei documenti nei quali
la frase "blood pressure" compare 10 o più volte nel campo full-text
Operatori di campo
In certi data base è possibile specificare
che la ricerca deve avvenire all'interno di un determinato campo e non
su tutti i campi.
Per esempio è possibile limitare la
ricerca ai soli campi Titolo, Autore o altro.
IN : permette di limitare la ricerca ad un campo specifico, eventualmente utilizzabile con l'opzione limit fields
Es.: American Collegiate Test in TI
(Stress and therapy) in
TI
Aphasia in DE
Cohen in AU
Operatori matematici
Si tratta di caratteri matematici utili per
delimitare ulteriormente la ricerca ai fini di un raffinamento legato ad
ambiti in cui vi possono essere riferimenti numerici, temporali, di lingua,
di paese e così via.
Non in tutti i campi è possibile adoperare
gli operatori matematici, ma solo nei campi limit fields.
Gli operatori matematici sono:
= uguale
> maggiore
< minore
=> uguale o maggiore
=< uguale o minore
- da ... a
* diverso da
Utili soprattutto per filtrare ulteriormente il risultato di una ricerca.
Es.: cell in TI and PY (Publication
Year) >1990
documenti con la parola cell
nel titolo pubblicati dal 1991
cell in TI and LA=italian
documenti in italiano con la parola
cell nel titolo
a cura di Antonella
De Robbio, 27 gennaio 1999