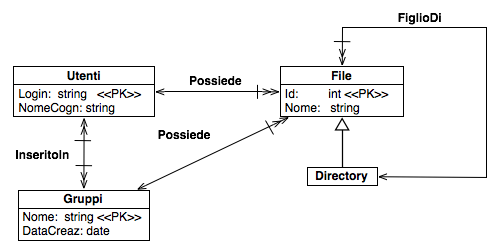
La terza esercitazione richiede la traduzione di un semplice modello concettuale ad oggetti nel modello relazionale, la definizione in SQL della base di dati, il suo popolamento ed infine la formulazione di alcune query. L'esercitazione nel suo complesso può richiedere più tempo di quello a disposizione.
Si presuppone la conoscenza della parte teorica discussa a lezione. Dubbi su MySQL possono essere risolti riferendosi alla MySQL Reference Guide. Nel caso questo non fosse sufficiente, sarò in laboratorio e possiamo discutere insieme di eventuali quesiti.
Nota: Durante la creazione e la popolazione della base di dati vi può essere utile (ad es. nel caso di riferimenti ciclici) inibire il controllo sulle chiavi esterne rispettivamente con
SET FOREIGN_KEY_CHECKS=0; e SET FOREIGN_KEY_CHECKS=1;
Id Nome Utente Gruppo
1 Radice/ root admin
11 Var/ root admin
111 Mail/ mail mail
1111 rossi.mbx rossi mail
1112 verdi.mbx verdi mail
112 SubM/ root admin
12 tmp/ root admin
121 tmp0.txt rossi user
122 tmp1.txt verdi user
123 SubT/ root admin
13 home/ root admin
131 rossi/ rossi user
1311 slide.txt rossi user
1312 progetto.pdf rossi user
132 verdi/ verdi user
1321 eserc1.sql rossi user
Alcune osservazioni
Gruppo Data
user 2007-01-02
mail 2006-01-01
admin 2006-02-04
sys 2006-12-25
none 2007-01-01
Gli utenti presenti, con i relativi gruppi di appartenenza sono
Login Nome Gruppi
root NULL user, mail, admin, sys, mail
verdi Gino Verdi user, mail
rossi Anna Rossi user, mail
mail NULL mail
nobody NULL
Ricordate che potete caricare le tabelle con il comando
INSERT INTO tabella VALUES ....oppure
LOAD DATA LOCAL INFILE 'file.txt' INTO TABLE tabelladove 'file.txt' e` un file preventivamente creato che contiene le ennuple da inserire in 'tabella', campi separati da TAB, per default, ma si possono specificare anche altri separatori.
Vi potrebbero essere utili i seguenti file (nei quali i campi sono separati da TAB ...)
Directory.txt GruppiUtenti.txt Utenti.txt File.txt Gruppi.txt
(Nota: Per poter usare il comando 'LOAD DATA ...' occorre aver avviato il client con il flag '--local-infile=1')
Ecco il file per la creazione ed il popolamento FileSystem.sql.Soluzioni: [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13]
Nota: Per scrivere ed eseguire le istruzioni SQL relative alle interrogazioni si puo`, al solito, creare un file query_n.sql per ciascuna query ed eseguirlo
Dal client MySQL può essere anche utile utilizzare il comando
\eche permette di editare la query corrente (o quella appena eseguita) in un editor a vostra scelta, cosi` come impostato nella variabile d'ambiente EDITOR. Qualora questa non fosse impostata, potete definirla inserendo nel file .bash_profile nella vostra home le righe
EDITOR=emacsSe il file non esistesse potete crearlo con il contenuto sopra indicato.
export EDITOR